Mysql数据源接入DBus
原理:
同步mysql数据源是通过 canal 抽取程序读取binlog的方式获得增量数据, 通过从mysql 备库以分片的方式scan数据来获得全量数据,最后转换为UMS 输出到kafka 提供给下游数据使用方使用。
环境说明:
- 环境中有dbus-n1,dbus-n2,dbus-n3三个节点,canal安装在了dbus-n1,dbus-n2中
- mysql数据源的主备分别是dbmysql-master和dbmysql-slave两个节点
- mysql_instance实例安装在上述两个节点dbmysql-master和dbmysql-slave上
下面从 mysql_instance实例中的test 库的 actor和actor2 表为例,介绍如何配置mysql数据源。
配置中用到的基础环境的情况请参考基础组件安装
如果只是加表,请参考加表流程
相关依赖部件说明:
dbus0.6.0
-
Canal :版本 v1.0.24 DBus用于实时抽取binlog日志。具体配置可参考canal相关支持说明,支持mysql5.6,5.7
-
DBus修改以下个文件,修改计数逻辑,修改json类型报错bug。
dbsync\src\main\java\com\taobao\tddl\dbsync\binlog\event\RowsLogBuffer.java dbsync\src\main\java\com\taobao\tddl\dbsync\binlog\JsonConversion.java parse\src\main\java\com\alibaba\otter\canal\parse\inbound\mysql\dbsync\LogEventConvert.java parse\src\main\java\com\alibaba\otter\canal\parse\inbound\AbstractEventParser.java
-
Mysql :版本 v5.6,v5.7 存储DBus管理相关信息
dbus0.6.1
- Canal :版本 v1.1.4 DBus用于实时抽取binlog日志。具体配置可参考canal相关支持说明,支持mysql5.6,5.7
限制:
-
被同步的Mysql blog 必须是row模式
MySQL [(none)]> show global variables like "%binlog_format%"; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | binlog_format | ROW | +---------------+-------+ 1 row in set (0.00 sec) -
考虑到kafka的message大小不宜太大,目前设置的是最大10MB,因此不支持同步mysql MEDIUUMTEXT/MediumBlob和LongTEXT/LongBlob, 即如果表中有这样类型的数据会直接被替换为空。
配置总共分为3个步骤:
- 数据库源端配置
- canal部署
- 加线和查看结果
1 数据库源端配置
数据库源端配置只在第一次配置环境时需要,在以后的加表流程中不需要再配置。
此步骤中需要在mysql数据源的mysql_instance实例上创建一个名字为dbus的库,并在此库下创建表db_heartbeat_monitor,用于心跳检测。
在数据源端新建的dbus库,可以实现无侵入方式接入多种数据源,业务系统无需任何修改,以无侵入性读取数据库系统的日志获得增量数据实时变化。
源端库和账户配置
在mysql_instance实例上,创建dbus 库以及数据表db_heartbeat_monitor;创建dbus用户,并为其赋予相应权限。
a) 创建dbus库和dbus用户及相应权限
--- 1 创建库,库大小由dba制定(可以很小,就2张表)
create database dbus;
--- 2 创建用户,密码由dba制定
CREATE USER 'dbus'@'%' IDENTIFIED BY 'Dbus$%^456';
--- 3 授权dbus用户访问dbus自己的库
GRANT ALL ON dbus.* TO dbus@'%' IDENTIFIED BY 'Dbus$%^456';
flush privileges;
b) 创建dbus库中需要包含的1张表,创建细节如下:
-- ----------------------------
-- Table structure for db_heartbeat_monitor
-- ----------------------------
DROP TABLE IF EXISTS `db_heartbeat_monitor`;
CREATE TABLE `db_heartbeat_monitor` (
`ID` bigint(19) NOT NULL AUTO_INCREMENT COMMENT '心跳表主键',
`DS_NAME` varchar(64) NOT NULL COMMENT '数据源名称',
`SCHEMA_NAME` varchar(64) NOT NULL COMMENT '用户名',
`TABLE_NAME` varchar(64) NOT NULL COMMENT '表名',
`PACKET` varchar(256) NOT NULL COMMENT '数据包',
`CREATE_TIME` datetime NOT NULL COMMENT '创建时间',
`UPDATE_TIME` datetime NOT NULL COMMENT '修改时间',
PRIMARY KEY (`ID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
SET FOREIGN_KEY_CHECKS=0;
c) dbus用户拉备库权限
获取拟拉取的目标表备库的读权限,用于初始化加载。以test_schema1.t1为例。
-- 1 创建测试库 测试表, 用于测试的.(已有的库不需要此步骤,仅作为示例)
create database test_schema1;
use test_schema1;
create table t1(a int, b varchar(50));
--- 2 创建测试用户,密码由dba制定。(已有的用户不需要此步骤,仅作为示例)
CREATE USER 'test_user'@'%' IDENTIFIED BY 'User!#%135';
GRANT ALL ON test_schema1.* TO test_user@'%' IDENTIFIED BY 'User!#%135';
flush privileges;
--- 3 授权dbus用户 可以访问 t1 的备库只读权限
GRANT select on test_schema1.t1 TO dbus;
flush privileges;
d) 在mysql数据源的mysql_instance实例中创建Canal用户,并授予相应权限:
--- 创建Canal用户,密码由dba指定, 此处为Canal&*(789
CREATE USER 'canal'@'%' IDENTIFIED BY 'Canal&*(789';
--- 授权给Canal用户
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
2 DBus一键加线
Dbus对每个DataSource数据源配置一条数据线,当要添加新的datasource时,需要新添加一条数据线。下面对通过dbus keeper页面添加新数据线的步骤进行介绍
2.1 数据源添加
(1) 管理员身份进入dbus 页面,数据源管理->新建数据线
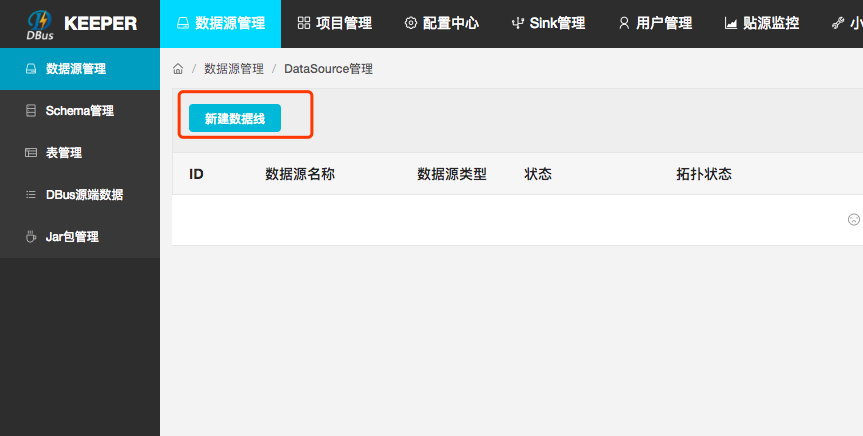
(2) 填写数据源基本信息 (master和slave jdbc连接串信息)
jdbc链接示例 jdbc:MySQL://localhost:3306/dbus?zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false
- 这里的数据库是上面创建的dbus数据库,和要抽取的数据库在同一个mysql实例
- 后缀建议加上我们提供的连个参数,否则可能会报错,其他参数根据数据库配置自行添加
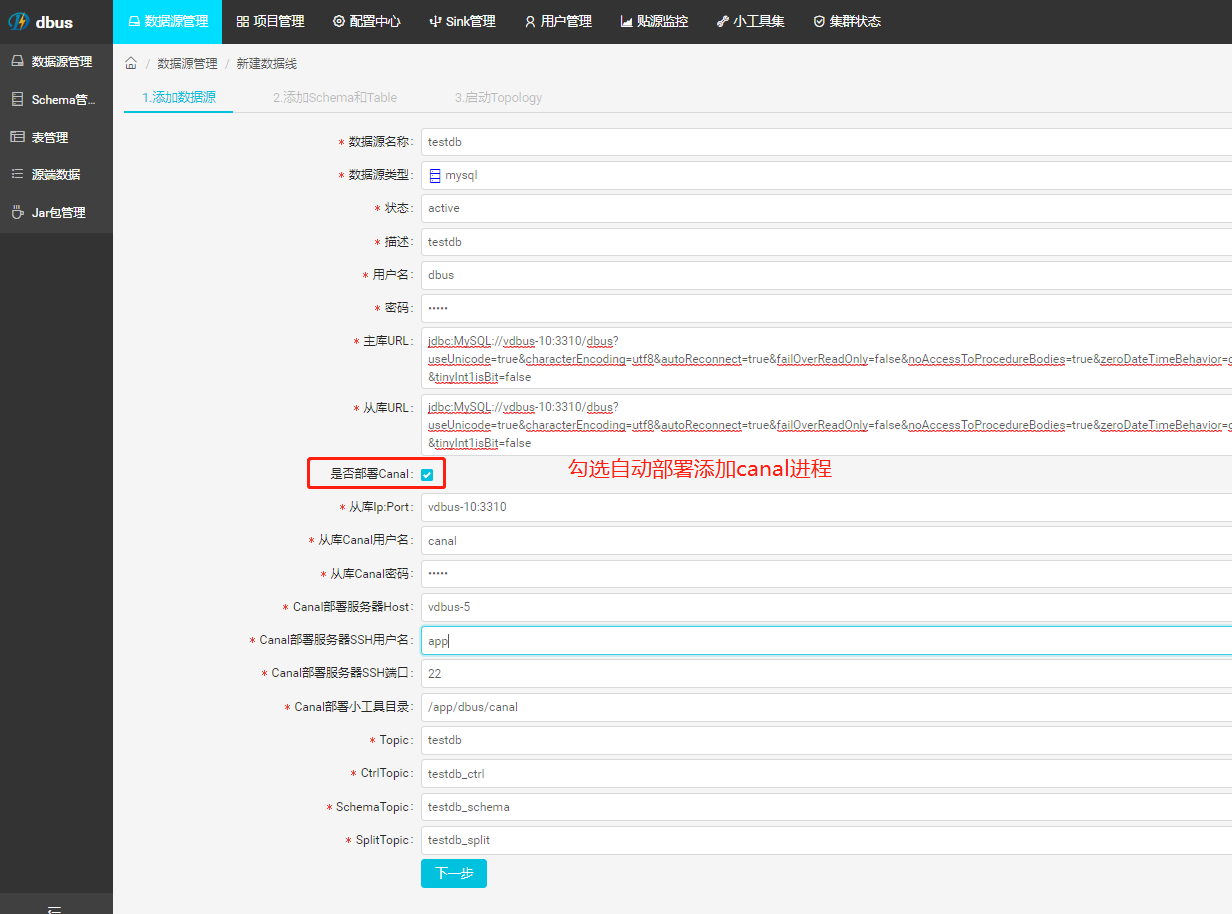
-
这里如果不勾选是否部署canal,则需要手动部署添加canal进程,不推荐
如需手动部署,请参考手动部署canal
!!!如有问题,请到logs目录下查看mgr.log和service.log获取具体问题原因.
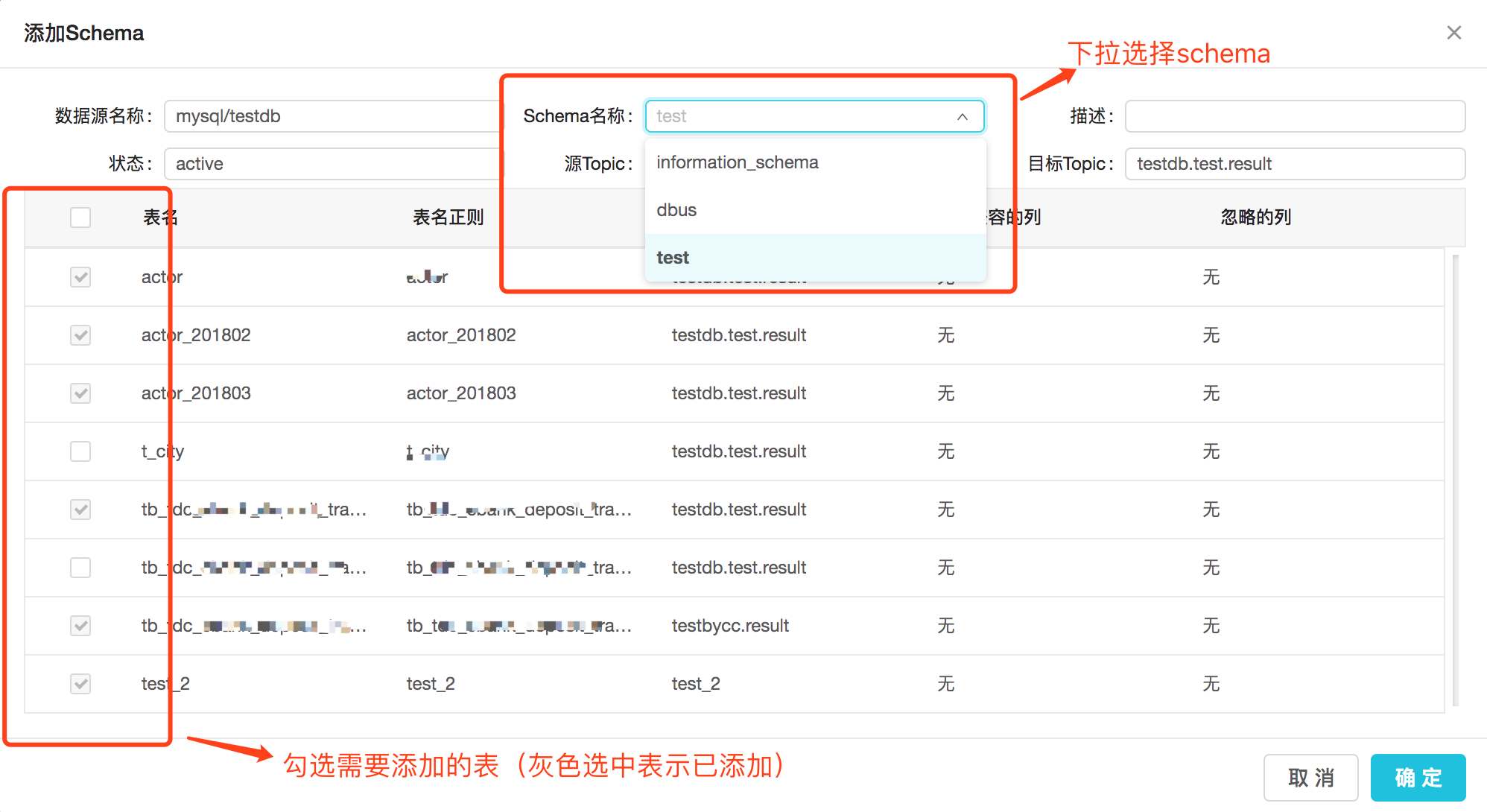
(3) 下拉选择要添加的schema,勾选要添加的表。Keeper支持一次添加多个schema下的多个table;
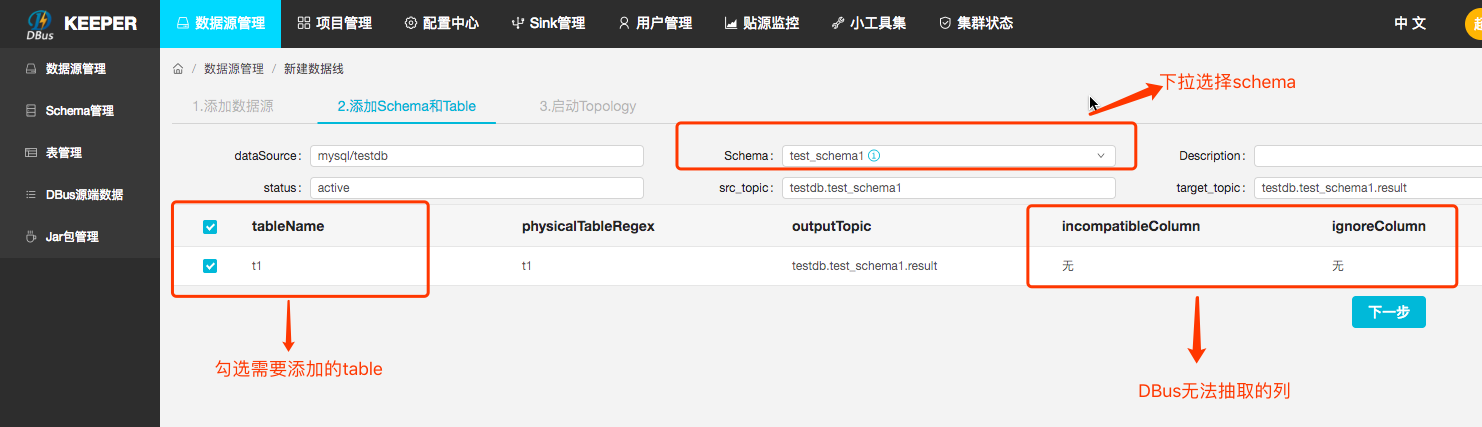
(4) 启动Topology
这里启动的是storm的worker进程,日志请到storm日志目录查看
增量数据流转:
dbus0.6.0
canal -> extractor -> 一级topic(数据线同名,例如:testdb)
-> dispatcher -> 二级topic(数据线.schema 例如:testdb.schema1)
-> appender -> 三级topic(数据线.schema.result 例如:testdb.schema1.result)
dbus0.6.1去掉了extractor模块,canal直接输出数据到kafka
canal -> 一级topic(数据线同名,例如:testdb)
-> dispatcher -> 二级topic(数据线.schema 例如:testdb.schema1)
-> appender -> 三级topic(数据线.schema.result 例如:testdb.schema1.result)
-
extractor 负责从canal消费数据写到第一级topic (!!!!0.6.1该模块废弃)
-
dispatcher-appender
dispatcher 分发器,负责消费一级topic数据,根据schema进行分发到多个二级topic
appender 增量数据处理器,负责消费二级topic数据,生成ums写到第三级topic,处理表结构变更等
-
splitter-puller 全量程序,负责初始化数据,数据丢失后数据补全
依次点击启动按钮启动各个进程

2.2 拉起增量和全量
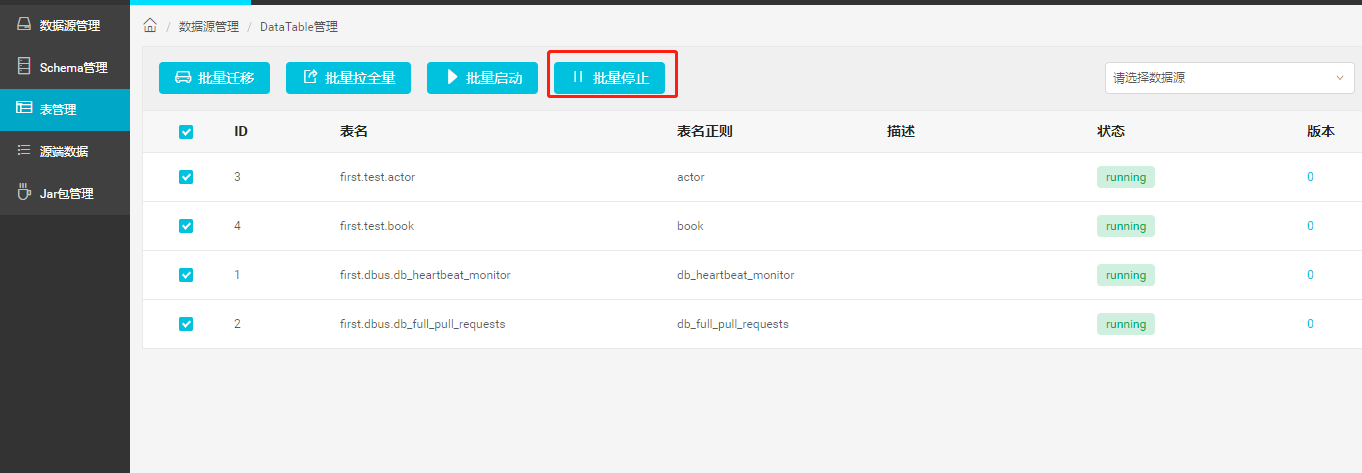
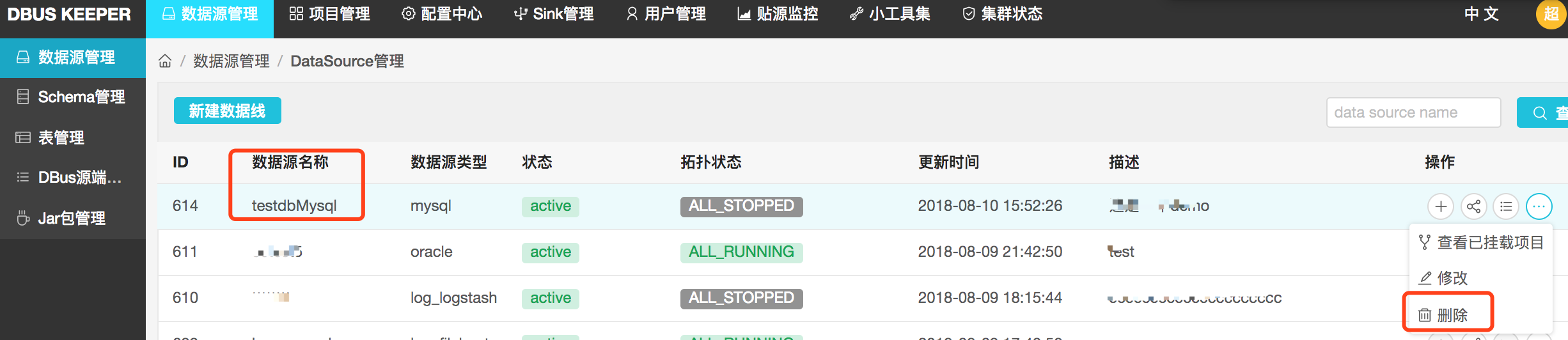
- 如果新加线过程中出现问题
如果新加线过程中出现问题时,可以先删除已经添加到一半的新线Datasource,然后再重新添加新线。
这里必须先停掉该数据线的所有表,才能删除数据线
2.2验证增量数据
2.2.1 插入数据
向数据源的数据表中添加数据,检验效果。此处以testdb数据源的test数据库的表actor中添加数据为例,向此表插入几条数据之后,会看到kafka UI中相应的topic: testdb, testdb.test, testdb.test.result的offset均有所增加。也可以在grafana中查看数据流的情况。
如果数据源中添加的schema和数据表已经存在数据,点击dbus web中的拉增量和拉全量,将现有数据同步到kafka中。
2.2.2 grafana查看增量流量
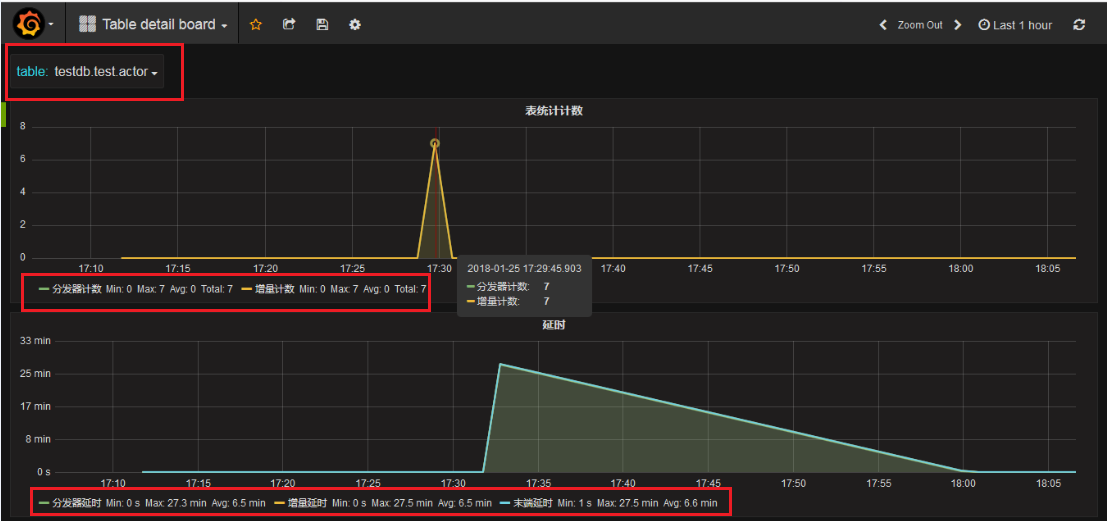
上述向数据表中添加完数据后,过大约几分钟,会在grafana中显示数据的处理情况。如下图中,两组则线图分别表示:计数和延时,正常情况下计数图中”分发计数器”和”增量计数器”两条线是重合的。在图左上角,选择要查看的数据表,此处为testdb.test.actor。上部的分发器计数图展示了此表的分发和增量程序接收到7条数据;下部的分发器延时展示分发延时、增量延时和末端延时情况。
2.2.3 数据验证失败问题排查
推荐方式二
2.4 验证全量数据
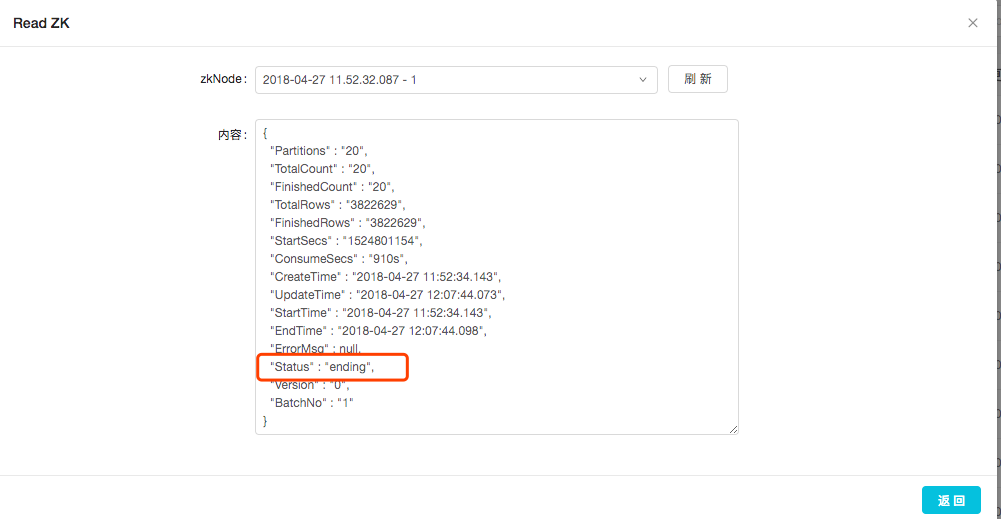
验证全量拉取是否成功,可在Table管理右侧操作栏,点击”查看拉全量状态”。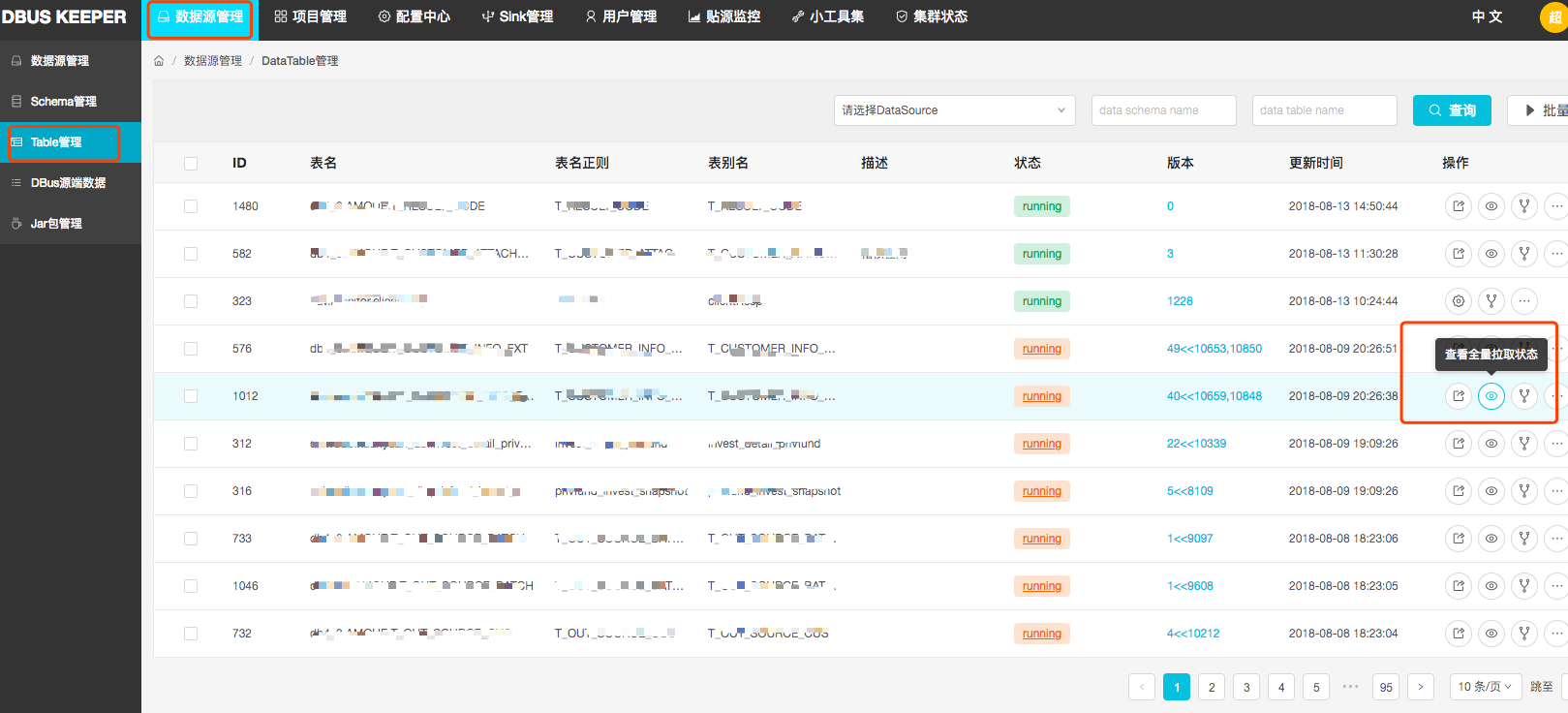 全量拉取的信息存储在ZK上,Dbus keeper会读取的zk下相应节点的信息,来查看全量拉取状态。看结点信息中Status字段,其中splitting表示正在分片,pulling表示正在拉取,ending表示拉取成功。
全量拉取的信息存储在ZK上,Dbus keeper会读取的zk下相应节点的信息,来查看全量拉取状态。看结点信息中Status字段,其中splitting表示正在分片,pulling表示正在拉取,ending表示拉取成功。
3 单独加表流程
本部分流程是建立在数据线部署完毕的基础上的,即在部署完数据线后,后续添加需要抽取的表。
3.1 加表入口
单独加表有两个入口:
一,在数据源管理–操作(添加schema),可以选择schema,然后选择要添加的table。此步骤与3.1中第三步操作一致(实际上是在加线的步骤中集成了加表的操作),可以选择多个schema下的多个table添加;
二,数据源管理–Schema管理–操作(添加table)。如果要添加的表都在一个schema下,或者您已确定需要添加哪个schema下的表,可以选择这个方式加表。
3.1.1 数据源管理入口
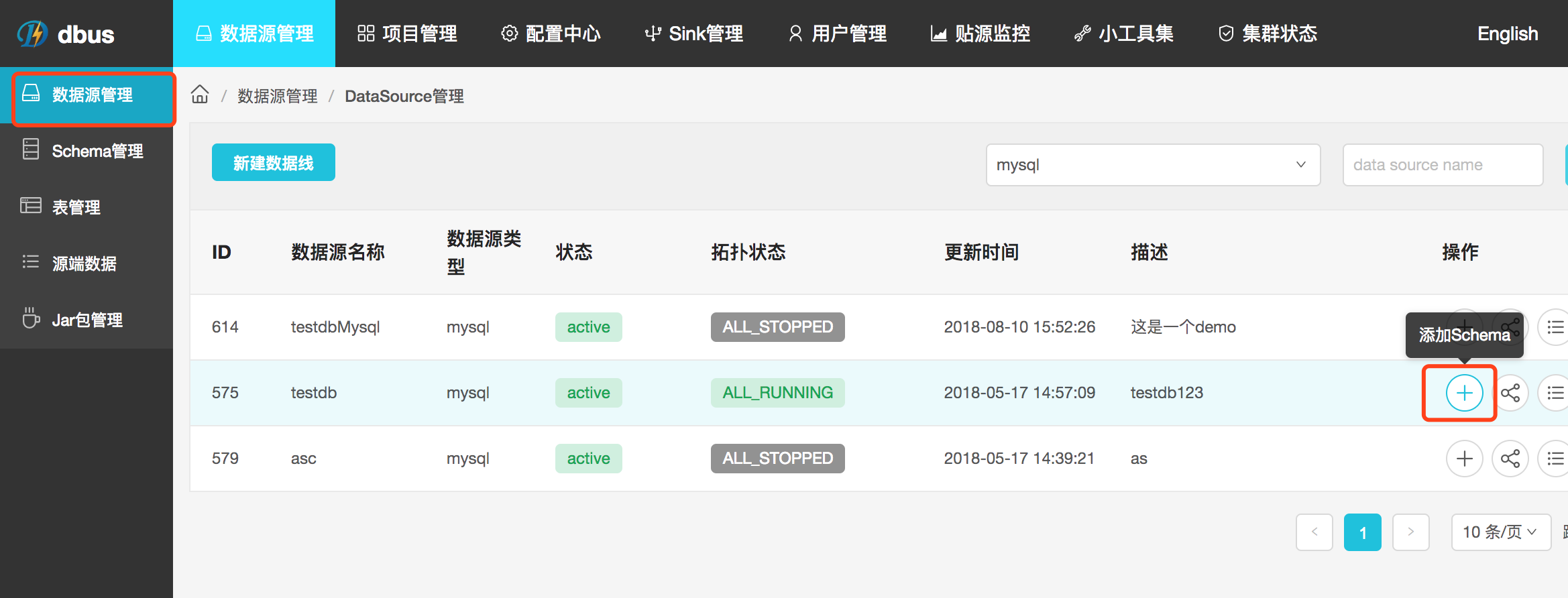
点击添加按钮后,可以进一步选择shcema和table进行操作,可选择多个schema的多个table
3.1.2 Schema管理入口
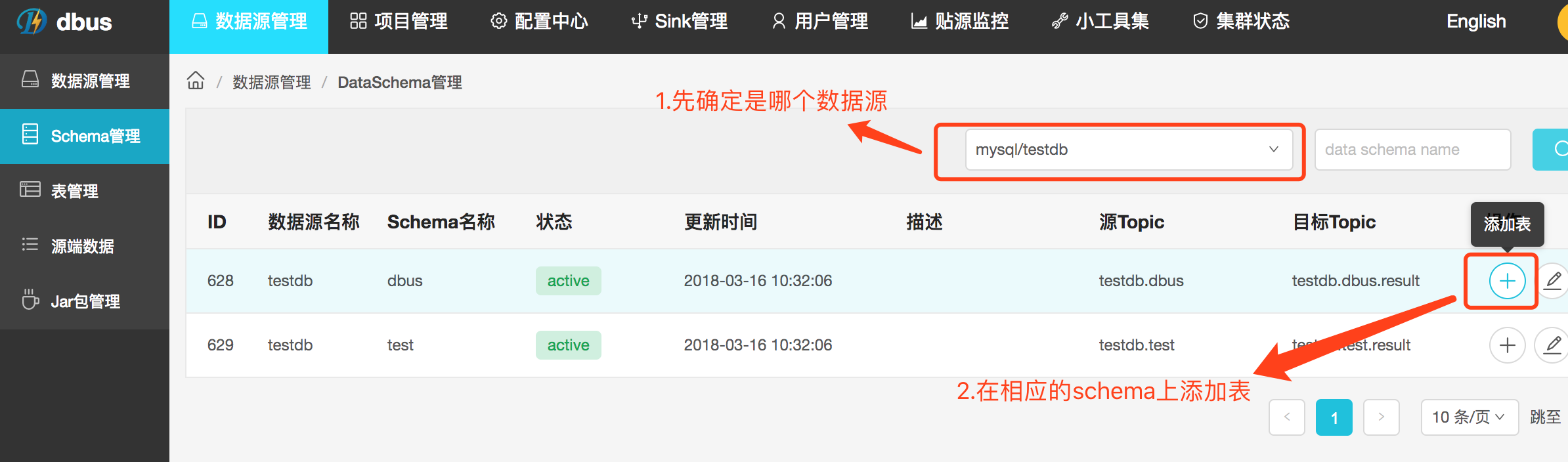
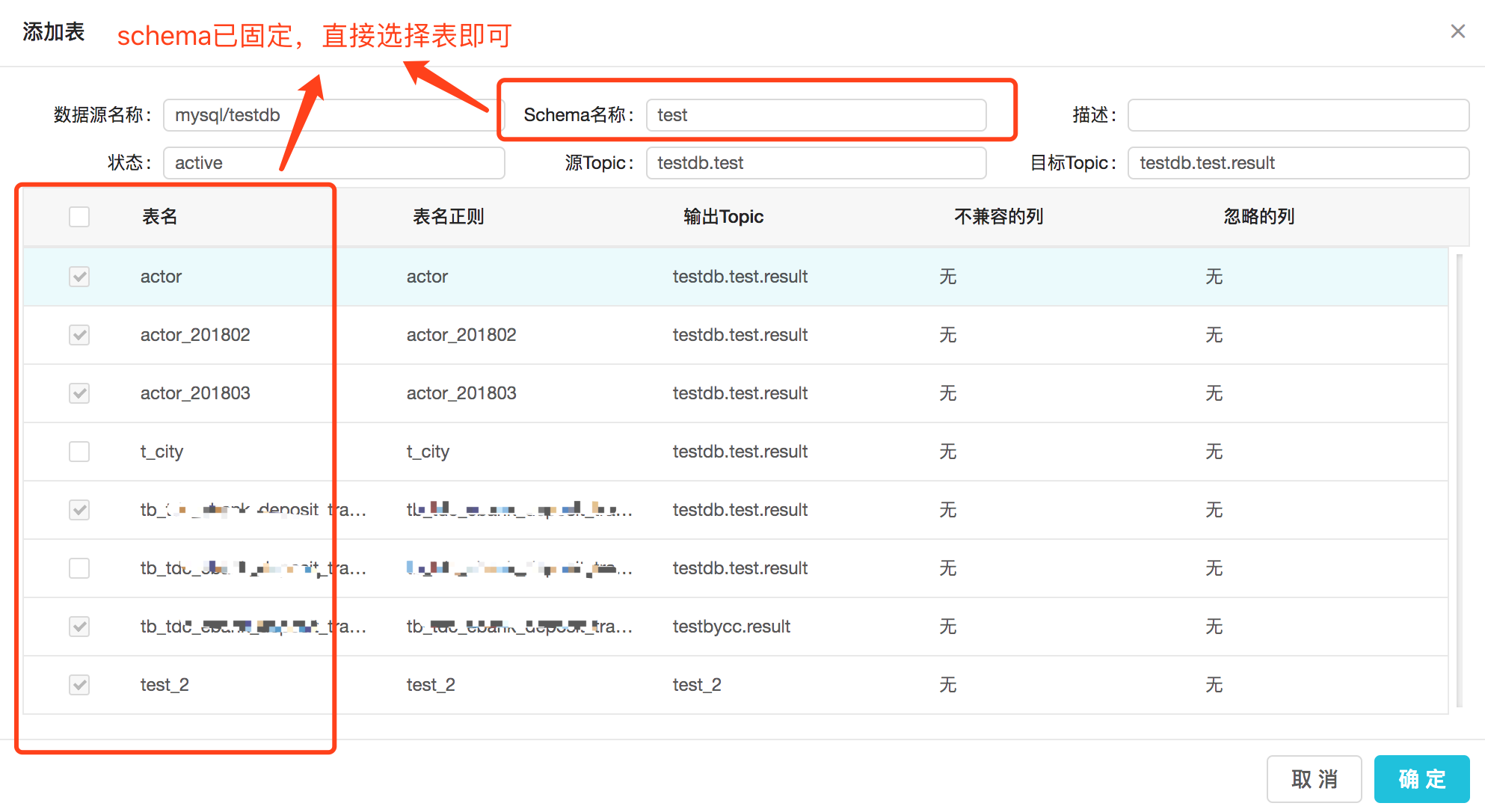
点击添加按钮后,直接选择table进行操作,因为schema已经固定。
4 附录
4.1 手动部署canal
4.1.1 上传并部署canal小工具
这里以 0.6.1版本为例
scp命令或者其他命令上传 zip目录下dbus-canal-auto-0.6.1.zip 和canal.zip 到目标机器的目标目录
这里举例 dbus-n1机器的 /app/dbus/canal目录
cd /app/dbus/canal
# 解压canal小工具
unzip dbus-canal-auto-0.6.1.zip
# 进入小工具
cd dbus-canal-auto-0.1.0
cp ../canal.zip .
unzip canal.zip
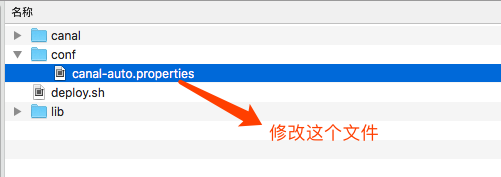
目录:
- canal目录是自带的canal,该文件夹不能重命名,否则脚本会运行失败。
- conf 目录下的canal-auto.properties是需要用户配置的
- lib 目录不用关心
- deploy.sh 自动化脚本
4.1.2 修改配置文件
- 修改conf目录下的canal-auto.properties文件中内。
例如:
#数据源名称,需要与dbus keeper中添加的一致
dsname=testdb
#zk地址,替换成自己的zk地址
zk.path=dbus-n1:2181
#canal 用户连接地址。即:要canal去同步的源端库的备库的地址
canal.address=dbus-n1:3306
#数据库canal用户名
canal.user=canal
#数据库canal密码,替换成自己配置的
canal.pwd=Canal&*(789
#canal slave id
canal.slaveId=1235
#0.6.1新加kafka配置
#bootstrap.servers,kafka地址
bootstrap.servers=vdbus-7:9092
4.1.3 校验配置文件
sh deploy.sh check
这里检验canal账户连通性、zk连通性、是否开启row模式日志等,报告信息会在“canal_check _report”打头的日志文件中保留一份,方便查看。
报告样例:
************ CANAL DEPLOY BEGIN! ************
数据源名称: testdb
zk地址: dbus-n1:2181
备库地址: dbus-n2:3306
canal 用户名: canal
canal 密码: canal
-----check database canal account begin
canal user: canal
canal pwd: canal
slave url: jdbc:mysql://dbus-n2:3306/dbus?characterEncoding=utf-8
数据库连接成功...
检查blog format: show variables like '%bin%'...
binlog_format : ROW
-----check database canal account success
------------ check canal zk node begin ------------
zk str: dbus-n1:2181
zk path : dbus-n1:2181
-----check canal zk path begin
node path: /DBus/Canal/testdb
path /DBus/Canal/testdb exist
-----check canal zk path end
------------ check canal zk node end ------------
------------ update canal.properties begin ------------
props: canal.port=10000
props: canal.zkServers=dbus-n1:2181/DBus/Canal/testdb
------------ update canal.properties end ------------
------------ update instance.properties begin ------------
instance file path /app/dbus/dbus-canal-auto-0.5.0/canal/conf/testdb/instance.properties
props: canal.instance.master.address=dbus-n1:2181
props: canal.instance.dbUsername=dbus
props: canal.instance.dbPassword =dbus
props: canal.instance.connectionCharset = UTF-8
------------ update canal.properties end ------------
------------ starting canal.....
exec: sh /app/dbus/dbus-canal-auto-0.5.0/canal/bin/stop.sh
exec: sh /app/dbus/dbus-canal-auto-0.5.0/canal/bin/startup.sh
exec: rm -f canal.log
exec: ln -s /app/dbus/dbus-canal-auto-0.5.0/canal/logs/canal/canal.log canal.log
exec: rm -f testdb.log
exec: ln -s /app/dbus/dbus-canal-auto-0.5.0/canal/logs/testdb/testdb.log testdb.log
exec: ps aux | grep "/Users/lxq/Desktop/Neo/dbus-canal-auto-0.5.0/canal/bin" | grep -v "grep" | awk '{print $2}'
canal 进程启动成功, pid 4647
请手动检查当前目录下canal.log,和testdb.log中有无错误信息。
************ CANAL DEPLOY SCCESS! ************
report文件: canal_deploy_report20180816152937.txt
4.1.4 执行部署脚本
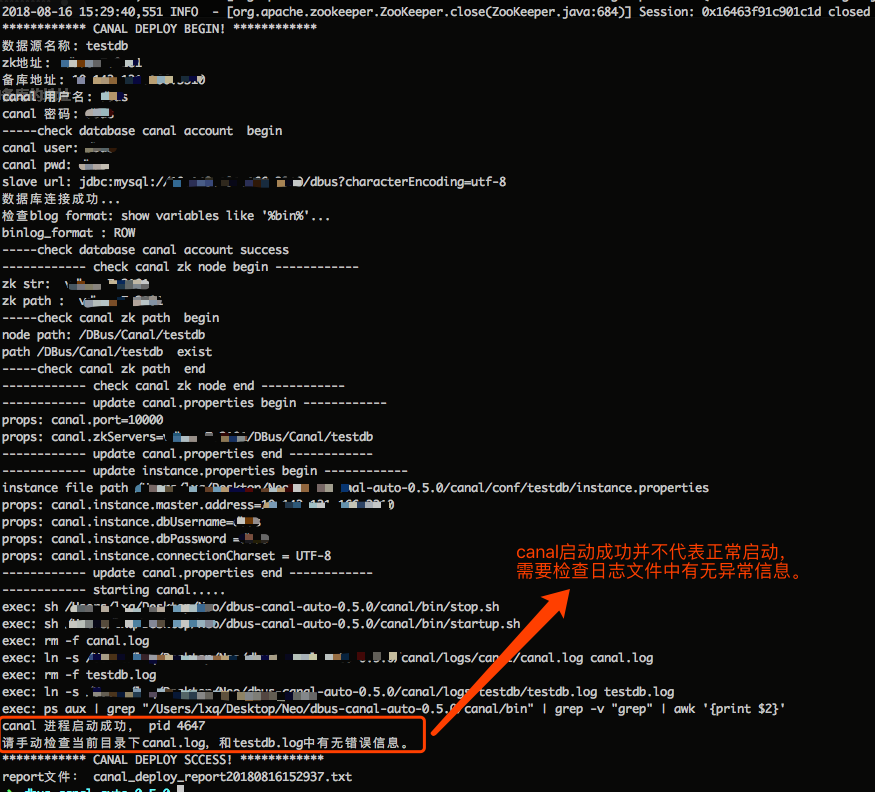
sh deploy.sh
如果启动成功,会打印出“canal 进程启动成功 ”字样,如下图所示。**但是canal进程在配置出错的情况下也能启动起来,所以最后需要检查下日志文件中是否有异常 **(脚本会在当前文件下创建日志文件的链接,可以直接查看)。同时,这些报告信息会在“canal_deploy _report”打头的日志文件中保留一份,方便查看。
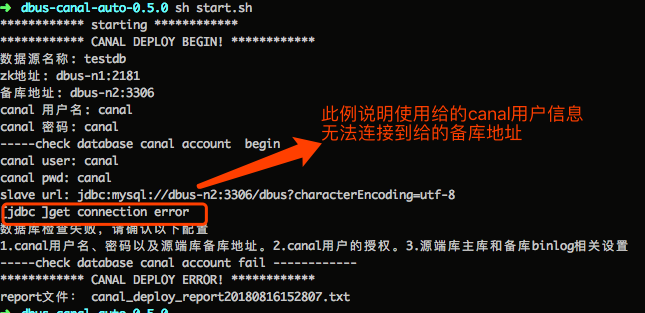
如果执行失败,信息会在某一步骤停止,说明某一部分有错。如下图所示,如果canal用户信息或备库库信息出错,则会出现数据库连接失败的情况。同时,这些信息也会在“canal_deploy _report”打头的日志文件中保留一份。
4.2 常见问题
4.2.1为什么检测通过还是失败
脚本提供的是常规性检测。检测仅帮助你进行初步的检测。除了检测报告,您还可以根据自动部署时创建的日志link,查看canal的日志,有时,虽然canal进程启动成功,但是其实是执行失败的,在日志里有错误详情。
4.2.2为什么自动部署失败
脚本提供的是在特定情况下,帮助简化安装部署步骤的。如果不能成功请根据异常信息查阅相关资料。
4.2.3为什么有些类型不支持呢
DBus系统会丢弃掉对大数据类型MEDIUMBLOB、LONGBLOB、LONGTEXT、MEDIUMTEXT等的支持,因为dbus系统假设最大的message大小为10MB,而这些类型的最大大小都超过了10MB大小。对canal源码的LogEventConvert.java进行了修改,丢掉了这些类型的数据。